
Okay… I did a thing.
A few days ago I touted a database concept. I then built out the initial concept. After this I did some further work and improved the concept. Today I can now release uDatabase, an ultra simple Unix-based database library in less than 256 lines of C.
From the readme (at the time of writing):
- Fast - It doesn’t try to do anything too smart, it just does one single thing well.
- Small - It is under 256 lines and uses minimal standard/Unix libraries. As a result it compiles at ~15kB.
- Threading - Thread safe and can be accessed via multiple threads (currently untested).
- RAM lookup - It minimizes time spent reading the disk by building a RAM lookup table and expands it as required.
- Dumb - It doesn’t do any magic.
It’s stupendously fast. How fast? During a 500k record test 1 it could write 25k records per second, read 28k records per second and deleted 40k records a second. This is all on really old hardware, writing on average 2.5kB per record.
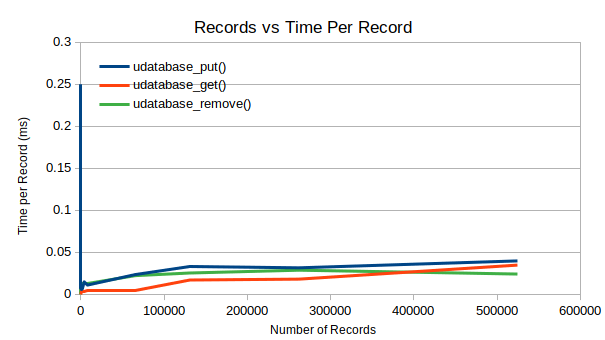
As you can see, the time per record processing is extremely fast and comes close to for a put, get and remove operation. Each record takes less that 50 microseconds to handle, with the average record during the 500k tests being 2.5kB in size.
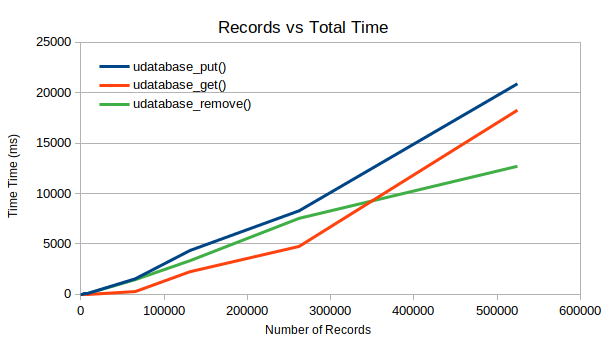
The total time to perform any of the put, get or remove operations is as low as 20 seconds for 500k records of 2.5kB each. In the previous update this took three times as long.
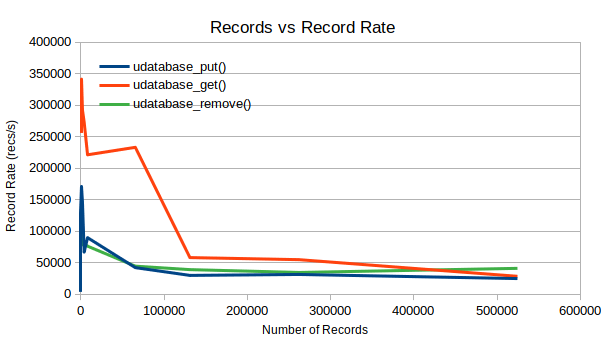
And as we confirmed previously, we hit approximately 25k records per second in the worst case, on my old busted hardware.
The raw results are as follows:
| Function | Records | ms | ms/record | records/sec |
|---|---|---|---|---|
| udatabase_put() | 4 | 1 ms | 0.250000 | 4000.000000 |
| udatabase_put() | 128 | 1 ms | 0.007812 | 128000.000000 |
| udatabase_put() | 256 | 2 ms | 0.007812 | 128000.000000 |
| udatabase_put() | 512 | 3 ms | 0.005859 | 170666.666667 |
| udatabase_put() | 1024 | 6 ms | 0.005859 | 170666.666667 |
| udatabase_put() | 2048 | 14 | 0.006836 | 146285.714286 |
| udatabase_put() | 4096 | 61 | 0.014893 | 67147.540984 |
| udatabase_put() | 8192 | 91 | 0.011108 | 90021.978022 |
| udatabase_put() | 65536 | 1545 | 0.023575 | 42418.122977 |
| udatabase_put() | 131072 | 4350 | 0.033188 | 30131.494253 |
| udatabase_put() | 262144 | 8287 | 0.031612 | 31633.160372 |
| udatabase_put() | 524288 | 20876 | 0.039818 | 25114.389730 |
| udatabase_get() | 4 | 0 | 0.000000 | inf |
| udatabase_get() | 128 | 0 | 0.000000 | inf |
| udatabase_get() | 256 | 0 | 0.000000 | inf |
| udatabase_get() | 512 | 2 | 0.003906 | 256000.000000 |
| udatabase_get() | 1024 | 3 | 0.002930 | 341333.333333 |
| udatabase_get() | 2048 | 7 | 0.003418 | 292571.428571 |
| udatabase_get() | 4096 | 15 | 0.003662 | 273066.666667 |
| udatabase_get() | 8192 | 37 | 0.004517 | 221405.405405 |
| udatabase_get() | 65536 | 281 | 0.004288 | 233224.199288 |
| udatabase_get() | 131072 | 2246 | 0.017136 | 58357.969724 |
| udatabase_get() | 262144 | 4759 | 0.018154 | 55083.841143 |
| udatabase_get() | 524288 | 18258 | 0.034824 | 28715.521963 |
| udatabase_remove() | 4 | 0 | 0.000000 | inf |
| udatabase_remove() | 128 | 2 | 0.015625 | 64000.000000 |
| udatabase_remove() | 256 | 2 | 0.007812 | 128000.000000 |
| udatabase_remove() | 512 | 6 | 0.011719 | 85333.333333 |
| udatabase_remove() | 1024 | 12 | 0.011719 | 85333.333333 |
| udatabase_remove() | 2048 | 26 | 0.012695 | 78769.230769 |
| udatabase_remove() | 4096 | 51 | 0.012451 | 80313.725490 |
| udatabase_remove() | 8192 | 107 | 0.013062 | 76560.747664 |
| udatabase_remove() | 65536 | 1464 | 0.022339 | 44765.027322 |
| udatabase_remove() | 131072 | 3338 | 0.025467 | 39266.626723 |
| udatabase_remove() | 262144 | 7541 | 0.028767 | 34762.498342 |
| udatabase_remove() | 524288 | 12699 | 0.024221 | 41285.770533 |
Is this any good? I have no freaking idea. There are really no apples-to-apples benchmarks out there…
I found this one report for Berkeley DB written by Oracle. On four different machines they got tonnes of different results.
I found another report on GitHub testing relational databases and soem of the results look somewhat similar?
I still have no idea.
Here I will discuss some insights I got and some nice to know stuff.
I haven’t tried profiling with C before, but it’s genuinely pretty
good. During compiling with gcc, you can add a
-pg flag to allow for profiling. Next you need to run your
program, which will generate a gmon.out file. After this
you can the convert it into something human readable with:
0001 gprof -b <BINARY> gmon.out > analysis.out
For uDatabase, analysis.out looks like so (I have cut it
to the first section of the output):
0002 Flat profile: 0003 0004 Each sample counts as 0.01 seconds. 0005 % cumulative self self total 0006 time seconds seconds calls ms/call ms/call name 0007 71.43 0.05 0.05 245388 0.00 0.00 udatabase_search 0008 28.57 0.07 0.02 5 4.00 4.00 udatabase_service 0009 0.00 0.07 0.00 245388 0.00 0.00 udatabase_shash 0010 0.00 0.07 0.00 163592 0.00 0.00 udatabase_remove 0011 0.00 0.07 0.00 81796 0.00 0.00 udatabase_get 0012 0.00 0.07 0.00 81796 0.00 0.00 udatabase_put 0013 0.00 0.07 0.00 54 0.00 0.00 currentTimeMillis 0014 0.00 0.07 0.00 1 0.00 0.00 udatabase_close 0015 0.00 0.07 0.00 1 0.00 0.00 udatabase_signal
Here you can see how much time is spent in each function, how many calls to each function and other cool stuff. This is a great way to benchmark your improvements when speeding up functions!
During profiling, I realised that udatabase_service()
got called often - in fact, way too often. The function is
responsible for expanding the lookup table, but we were doing it
insanely often. It’s a very heavy function as it also cleans up
the database on disk at the same time.
I initially used __unint128_t, but this is both not
compiler portable or even system portable. I ended up switching to a
char* as all we were essentially doing was byte
matching.
After some time, it occurred to me that we were getting tonnes of
hash collisions, causing udatabase_service() to get called
to expand the lookup table, and then pay massive overheads from this
function.
My initial hash function was as follows:
0016 /**
0017 * udatabase_shash() Convert a string to a hash.
0018 * Source: http://www.cse.yorku.ca/~oz/hash.html
0019 * @param s The NULL terminated string to be hashed.
0020 * @return The hashed number.
0021 **/
0022 __uint128_t udatabase_shash(char* s){
0023 __uint128_t h = 0;
0024 int c;
0025 while(c = *s++) h = c + (h << 6) + (h << 16) - h;
0026 return h;
0027 }
This worked well, except I no longer wanted to rely on the
__uint128_t type.
Next I implemented string-based hashing and cooked up the following:
0028 /**
0029 * udatabase_shash() Convert a string to a hash.
0030 * @param s The NULL terminated string to be hashed.
0031 * @param d The target pre-allocated string of hash length for the result.
0032 * @param n The length of the hash to be created.
0033 * @return A pointer to the hashed string stored in d.
0034 **/
0035 char* udatabase_shash(char* s, char* d, int n){
0036 int x = -1;
0037 while(s[++x]) d[x % n] = s[x] ^ (x < n ? '\0' : d[x % n] << 2);
0038 while(x < n) d[x++] = '\0';
0039 return d;
0040 }
It worked fine during small test cases, but absolutely sucked in the larger tests… I got a little better performance with:
0041 while(s[++x]) d[x % n] = s[x] ^ (s[x + 1] << 3);
But it still sucked for large scale tests…
Then it hit me! Out of the result of this function (which we’ll call
hash), we pull out the first two bytes and use it as a
short hash like so: *(uint16_t*)hash. We then use this
short form for our initial testing for matches and our lookup table
acceleration.
The problem is, with the previous version of the hashing function, the first two bytes are really low entropy! What of there was a way to force high entropy onto the first two bytes… There is!
0042 /**
0043 * udatabase_shash() Convert a string to a hash.
0044 * @param s The NULL terminated string to be hashed.
0045 * @param d The target pre-allocated string of hash length for the result.
0046 * @param n The length of the hash to be created.
0047 * @return A pointer to the hashed string stored in d.
0048 **/
0049 char* udatabase_shash(char* s, char* d, int n){
0050 int x = -1;
0051 while(s[++x]){
0052 d[x % n] = s[x];
0053 d[x % sizeof(uint16_t)] ^= s[x] << 3;
0054 }
0055 while(x < n) d[x++] = '\0';
0056 return d;
0057 }
This works extremely well! I’m not away of any other C (or other language) string->string hash function, and certainly of nothing that prioritizes entropy in the first bits in order for a simple shortening cast to take advantage of.
memcmp()Holy moly I wish I had known about this function sooner! My initial string comparison looked like this:
0058 /**
0059 * udatabase_cmp() Compare two binary strings of equal length.
0060 * @param a The first string to be compared.
0061 * @param b The second string to be compared.
0062 * @param n The length of the strings to be compared.
0063 * @return If strings are equal return 0, otherwise not equal.
0064 **/
0065 int udatabase_cmp(char* a, char* b, int n){
0066 while(n-->0) if(*a++ != *b++) break;
0067 return n + 1;
0068 }
It’s ‘okay’, but there’s a lot of checking going on in there. I did
some checking online and in theory it is possible to do zero-branching
string compare for fixed-length strings… But someone (cannot remember
who) suggested just to forget that and checkout memcmp()
instead! It’s super speedy!
Another plus is it has example the same definition and meant that I could delete my comparison function entirely!
Okay, this was a stroke of genius. There are a few great points with this code:
SIGHUP and
SIGKILL, and all implementations I could find number these
roughly between 1 to 9, in that order. All the signal in between were
also pretty interesting, so with a single line, we can register our
interest in them all!FILE* to close the database.
This is stored in a database struct uDB. Our
close() function should be able to be called by anybody,
including the signal handler. So the question is, how do we give the
function udatabase_signal() a reference to db
when parameters are not supported for the signal handler? Check this
out…0069 for(int x = SIGHUP; x < SIGKILL; x++) signal(x, (void (*)(int))udatabase_signal); 0070 udatabase_signal(0, db);
After setting up the signals of interest, we hand over a fake signal
with access to our db struct.
0071 /**
0072 * udatabase_signal() Handle a given signal and close gracefully.
0073 * @param db The database description.
0074 * @param signum The signal number indicating
0075 * @param ptr The raw pointer to the database structure.
0076 **/
0077 void udatabase_signal(int signum, void* ptr){
0078 static struct uDB* db = NULL;
0079 if((db = db != NULL ? db : ptr) != NULL && signum >= SIGHUP && signum <= SIGKILL)
0080 udatabase_close(db); // NOTE: Remains locked.
0081 }
We then read this into a static variable if we detect we have not already stored it! I still need to see exactly how this will work with multiple databases opened though… I suspect it won’t work.
There is an example implementation that uses most of the functions and allows you to perform performance tests.
The following are the main functions (at the time of writing) that I expect people to use. They are ordered in roughly the order you may choose to use them.
0082 /** 0083 * udatabase_create() Create a database on disk and closes it. 0084 * @param filename The location of the database to be create. 0085 **/ 0086 void udatabase_create(char* filename);
udatabase_create() - Create a new database with a given
filename. This essentially just creates a file if one
doesn’t already exist 2.
0087 /** 0088 * udatabase_init() Open a database for read/write operations. 0089 * @param db The database description pointer. 0090 * @param filename The location of the database to be operated on. 0091 * @param width The width of an entire record. 0092 **/ 0093 void udatabase_init(struct uDB* db, char* filename, long int width);
udatabase_init() - Load a database from disk with a
given filename, into a database structure db
(allocation of structure memory handled by user), with entries on disk
of a given width. The purpose of having db is
to allow multiple databases to be opened at the same time (although this
is currently untested 3).
0094 /** 0095 * udatabase_put() Store value using key. No check if the key already exists. 0096 * @param db The database description. 0097 * @param k A NULL terminated key string to be used to insert a value. 0098 * @param v A string to be inserted into the database. 0099 * @param n The length of the string to be stored. 0100 * @return The success of the insertion. 0101 **/ 0102 int udatabase_put(struct uDB* db, char* k, char* v, long int n);
udatabase_put() - Put a new record into the database
db, with key k, payload value v,
of payload length n. v doesn’t have to be
NULL terminated, and if not, you should have a way of
figuring out the length once it’s retrieved if it’s not of fixed
length.
0103 /** 0104 * udatabase_search() Search for an entry in the database given a key. 0105 * @param db The database description. 0106 * @param k A NULL terminated key string value to be searched for. 0107 * @param kHash The already hashed key, otherwise NULL. 0108 * @return The table offset with correct fseek(), -1 not found. 0109 **/ 0110 long int udatabase_search(struct uDB* db, char* k, char* kHash);
udatabase_search() - Search for an entry in the database
db, given a key k, and pre-computed hash
kHash (otherwise just set NULL). If the entry
is found, you will be a value
,
otherwise
.
The disk will also be setup to this location.
This function can be used to check whether an entry exists or not.
Note: If you call this function you will be responsible for releasing the lock, as it keeps it open for the caller thread as not to let the disk position be changed.
0111 /** 0112 * udatabase_get() Get the data stored at the location if it exists. 0113 * @param db The database description. 0114 * @param k A NULL terminated key string value to be searched for. 0115 * @return The malloc'd value associated with the key, otherwise NULL. 0116 **/ 0117 char* udatabase_get(struct uDB* db, char* k);
udatabase_get() - Get a value from the database
db given a key k, otherwise NULL
if it could not be found.
Note: The returned value is malloc()’d,
so the caller must run free() on it once finished with
it.
0118 /** 0119 * udatabase_remove() Remove a given record and all related entries. 0120 * @param db The database description. 0121 * @oaram k The key to be matched for the entry. 0122 * @param kHash The already hashed key, otherwise NULL. 0123 * @return The table offset, -1 not found. 0124 **/ 0125 long int udatabase_remove(struct uDB* db, char* k, char* kHash);
udatabase_remove() - Remove an entry from the database
db using key k. If the hash for the key is
already computed, this can be given using kHash, otherwise
set to NULL. The function returns the offset into the
table.
Note: If you call this function you will be responsible for releasing the lock, as it keeps it open for the caller thread as not to let the table position be changed.
0126 /** 0127 * udatabase_service() Compress empty records and rebuild lookup. 0128 * @param db The database description. 0129 * @return 0 on success, otherwise -1 if another service required. 0130 **/ 0131 int udatabase_service(struct uDB* db);
udatabase_service() - Perform servicing on database
db. This function is called automatically, but may also be
called periodically if the database is using too much disk space. This
function will take a while to complete depending on which much clean-up
work is required.
0132 /** 0133 * udatabase_close() Close the database and stop further operation. 0134 * @param db The database description. 0135 * @return The success of closing. 0136 **/ 0137 int udatabase_close(struct uDB* db);
udatabase_close() - Close the database db
and keep in a locked state, so that no other operation may be
performed.
That’s enough from me for now! As mentioned in the uServer project this is all part of a larger ongoing effort.
I will need to think of a project to put both uServer and uDatabase together, and run them through their paces in a live system. That’s the best way to find bugs after all!