
A few days ago I mentioned the intention to flesh out a micro database library as part of my single file header libraries, a project to build small and simple Unix libraries for doing simple tasks really well.
I spent about a day coding some stuff and got something working - but it’s not nearly at a point where I would trust it or want to use it!
It has the following features currently:
If it wasn’t for some performance issues, it would actually be reasonably serviceable!
0001 /** 0002 * udatabase_shash() Convert a string to a hash. 0003 * Source: http://www.cse.yorku.ca/~oz/hash.html 0004 * @param s The NULL terminated string to be hashed. 0005 * @return The hashed number. 0006 **/ 0007 __uint128_t udatabase_shash(char* s); 0008 0009 /** 0010 * udatabase_sfind() Find a character in a NULL terminated string. 0011 * @param a The string to be searched. 0012 * @param c The character to be located. 0013 * @return Pointer to the character, otherwise the end of the string. 0014 **/ 0015 char* udatabase_sfind(char* a, char c); 0016 0017 /** 0018 * udatabase_scmp() Compare two NULL terminated strings, checking if equal. 0019 * @param a The first string to be checked. 0020 * @param b The substring to be checked that is NULL terminated. 0021 * @param c Treat as a NULL character in string a. 0022 * @return A pointer to the end of the match if equal, otherwise NULL. 0023 **/ 0024 char* udatabase_scmp(char* a, char* b, char c); 0025 0026 /** 0027 * udatabase_search() Search for an entry in the database given a key. 0028 * @param k A NULL terminated key string value to be searched for. 0029 * @param off Offset to begin the search. 0030 * @return The offset into the database and setup fseek(), otherwise -1. 0031 **/ 0032 long int udatabase_search(char* k, long int off); 0033 0034 /** 0035 * udatabase_get() Get the data stored at the location if it exists. 0036 * @param k A NULL terminated key string value to be searched for. 0037 * @return The malloc'd value associated with the key, otherwise NULL. 0038 **/ 0039 char* udatabase_get(char* k); 0040 0041 /** 0042 * udatabase_put() Store value using key. No check if the key already exists. 0043 * @param k A NULL terminated key string to be used to insert a value. 0044 * @param v A string to be inserted into the database. 0045 * @param n The length of the string to be stored. 0046 * @return The success of the insertion. 0047 **/ 0048 int udatabase_put(char* k, char* v, int n); 0049 0050 /** 0051 * udatabase_close() Close the database and stop further operation. 0052 * @return The success of closing. 0053 **/ 0054 int udatabase_close(); 0055 0056 /** 0057 * udatabase_init() Open a database for read/write operations. 0058 * @param filename The location of the database to be operated on. 0059 * @return Initialisation success result. 0060 **/ 0061 int udatabase_init(char* filename); 0062 0063 /** 0064 * udatabase_create() Create a database on disk and closes it. 0065 * @param filename The location of the database to be create. 0066 * @param width The width of each entry in the database (max 2^16). 0067 * @return Creation success result. 0068 **/ 0069 int udatabase_create(char* filename, int width); 0070 0071 /** 0072 * udatabase_compress() Compress the database to make use of deleted records. 0073 * @return 0 on success, otherwise -1 on error. 0074 **/ 0075 int udatabase_compress();
A few points to note from the original design concept:
__uint128_t - I decided to use __uint128_t
to store hash values in - it’s the largest integer that is currently
supported by a compiler. It means that in theory our integer
calculations should be quite fast, but does lock us into 64-bit
operating systems only. I may still look to change this. The use of
explicitly set number of bits is very important though, as it
means the database is accessed in a reliable way.udatabase_shash() - It doesn’t make sense to be able to
set the bits for the has function, we should just generate a large hash
and use modulo to cut it down to size.udatabase_search() - This new function finds the first
instance of a given key and returns the raw offset in the database. As
well as finding the location of records, this can be used as an
exist() type function for checking whether a key is
present. We will discuss this function later.udatabase_put() - This function now excepts a length
for the data. The importance is to allow larger than the set record
length to be added to the database.udatabase_compress() - This is a new function that will
allow the database to be reduced in size, encase there is some deleted
records. The implementer then is able to control when this operation is
performed as it will create a small amount of downtime as disk space is
saved. In some applications, saving disk space may not even be a
requirement, therefore the operation does not need to be performed.One thing I am not happy with is the fact that the internal database variables are accessible from the outside. I will at some point figure out a way to make these ‘private’ encase somebody attempts to use them as part of the library.
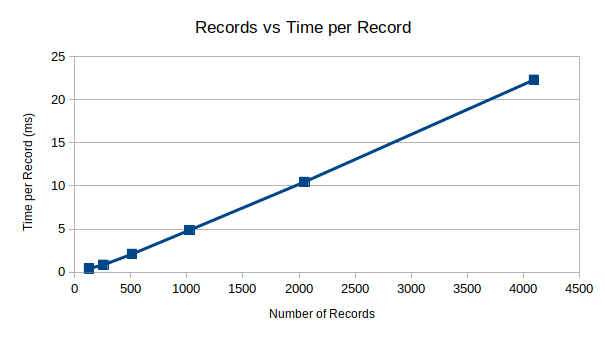
I performed some initial benchmarks for putting data into the database, and got the following results:
| Function | Records | ms | ms/record |
|---|---|---|---|
udatabase_put() |
128 | 57 | 0.445312 |
udatabase_put() |
256 | 218 | 0.851562 |
udatabase_put() |
512 | 1079 | 2.107422 |
udatabase_put() |
1024 | 5000 | 4.882812 |
udatabase_put() |
2048 | 21417 | 10.457520 |
udatabase_put() |
4096 | 91334 | 22.298340 |
Instead of the
performance I wanted, instead we have
performance. This is because there is currently no caching, and when we
initially perform the udatabase_put() function, it calls
udatabase_search() which manually searched the database. As
the database grows, so does the time to enter data.
Worst still is the total time, where we see something like cost as the number of records increases. Obviously, something must be done!
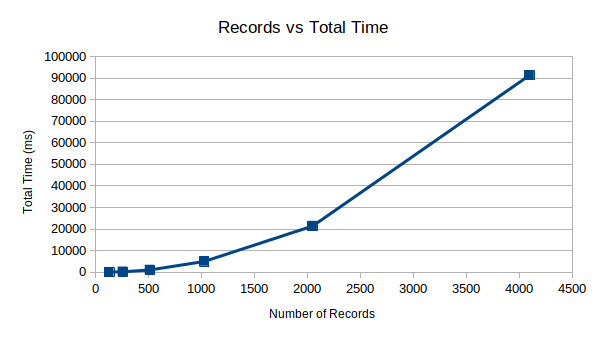
My initial guess is that we can actually get these times to something like 0.001 ms per record with near performance using a RAM-based cache system as mentioned in the concept article.
I have the following future intentions:
That’s all for now folks!