
Yeah… I wasn’t expecting to have an update on this so quickly, but after some sleep and some new round of motivation, I quickly addressed some of the previous issues raised.
There have been a series of changes, but I’ll just list them out here and give an overview of why they were done:
udatabase_sfind() and
udatabase_scmp() - These functions were not in use and
just using up valuable line space.udatabase_remove() testing bug - Turns out
the database cannot remove what you do not ask it to remove.udatabase_service() -
Reclaim empty positions in the database, as well as rebuild the RAM
lookup table mapping.There are likely a few other things, but that’s all I can think of for now.
As you can see, we now have performance measures for
udatabase_put(), udatabase_get(),
udatabase_remove() - the main database functions we expect
to spend the majority of our time. Instead of just testing 4k records,
we now test 500k records. Compared to the previous results, we will make
some comparisons…
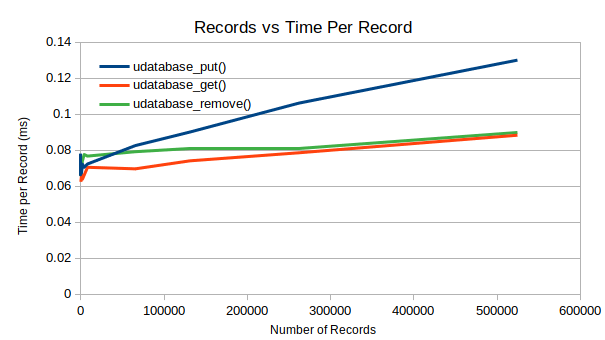
udatabase_put() is still
,
but is significantly faster than previously documented.
udatabase_put() needs to search for previous entries,
delete them, then write a new entry. It’s quite a costly operation.
udatabase_get() and udatabase_remove() are
much cheaper operations though and are closer to
as they can make use of the RAM lookup table.
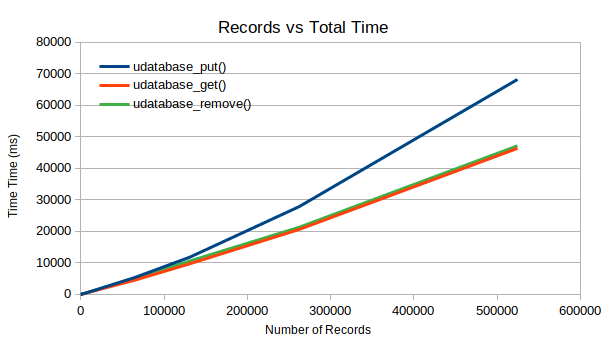
The total time taken to perform a bulk of operations is now closer to (rather than as it was previously).
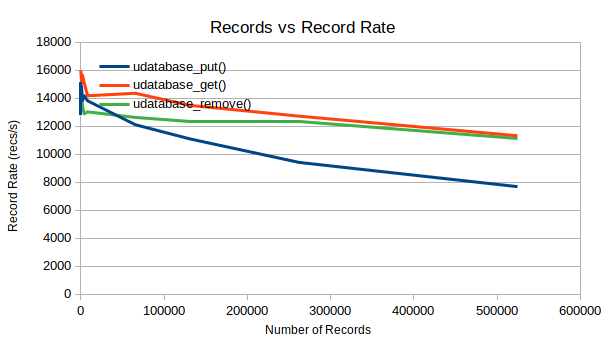
One last measurement is records per second, which describes how many records can be processed in a second. I believe this is the most important metric when comparing against other databases.
As for performance, during testing we were using at most 0.2% of my very old i76700HQ CPU, and approximately 20MB of RAM. I believe it is fair to say that our biggest issue currently is disk performance, where all tests are being performed on an old spinning drive.
Raw data:
| Function | Records | ms | ms/record | records/sec |
|---|---|---|---|---|
udatabase_put() |
128 | 10 | 0.078125 | 12800.000000 |
udatabase_put() |
256 | 17 | 0.066406 | 15058.823529 |
udatabase_put() |
512 | 35 | 0.068359 | 14628.571429 |
udatabase_put() |
1024 | 69 | 0.067383 | 14840.579710 |
udatabase_put() |
2048 | 148 | 0.072266 | 13837.837838 |
udatabase_put() |
4096 | 289 | 0.070557 | 14173.010381 |
udatabase_put() |
8192 | 593 | 0.072388 | 13814.502530 |
udatabase_put() |
65536 | 5413 | 0.082596 | 12107.149455 |
udatabase_put() |
131072 | 11812 | 0.090118 | 11096.512022 |
udatabase_put() |
262144 | 27836 | 0.106186 | 9417.445035 |
udatabase_put() |
524288 | 68178 | 0.130039 | 7689.987973 |
udatabase_get() |
128 | 8 | 0.062500 | 16000.000000 |
udatabase_get() |
256 | 16 | 0.062500 | 16000.000000 |
udatabase_get() |
512 | 32 | 0.062500 | 16000.000000 |
udatabase_get() |
1024 | 68 | 0.066406 | 15058.823529 |
udatabase_get() |
2048 | 131 | 0.063965 | 15633.587786 |
udatabase_get() |
4096 | 271 | 0.066162 | 15114.391144 |
udatabase_get() |
8192 | 578 | 0.070557 | 14173.010381 |
udatabase_get() |
65536 | 4567 | 0.069687 | 14349.901467 |
udatabase_get() |
131072 | 9716 | 0.074127 | 13490.325237 |
udatabase_get() |
262144 | 20609 | 0.078617 | 12719.879664 |
udatabase_get() |
524288 | 46317 | 0.088343 | 11319.558693 |
udatabase_remove() |
128 | 9 | 0.070312 | 14222.222222 |
udatabase_remove() |
256 | 17 | 0.066406 | 15058.823529 |
udatabase_remove() |
512 | 37 | 0.072266 | 13837.837838 |
udatabase_remove() |
1024 | 72 | 0.070312 | 14222.222222 |
udatabase_remove() |
2048 | 152 | 0.074219 | 13473.684211 |
udatabase_remove() |
4096 | 318 | 0.077637 | 12880.503145 |
udatabase_remove() |
8192 | 629 | 0.076782 | 13023.847377 |
udatabase_remove() |
65536 | 5190 | 0.079193 | 12627.360308 |
udatabase_remove() |
131072 | 10601 | 0.080879 | 12364.116593 |
udatabase_remove() |
262144 | 21289 | 0.081211 | 12313.589178 |
udatabase_remove() |
524288 | 47117 | 0.089869 | 11127.363797 |
There is a little more work to go before I am happy to release this project. It’s quite important that this project works correctly, people don’t like databases that lose data!
I hope to get a little more speed-up, fix the integer widths, reduce hashing performed and reduce disk I/O. Once there is more speed-up, I should then be able to run more large-scale tests.