
I use a custom script to pull my nginx logs, manipulate them and then graph the results for the website. It is responsible for a few tasks:
scp.nginx-parser
program to process and visualise the logs.This system has been getting slower over the years, to the point where it now takes the best part of a day to process the logs. This both uses significant system resources and means that I cannot access important data for quite some time.
How large is the data?
0001 $ ls -lh storage.txt 0002 1.5G storage.txt 0003 $ wc -l storage.txt 0004 7100816 storage.txt
1.5 GB and 7 million entries being processed by an old bash script. Yikes. Time to do some debugging.
The first task was to add some timing code:
0005 # Time variables
0006 time_beg=0
0007 time_end=0
0008 time_run=0
0009
0010 # time_start()
0011 #
0012 # Begin timing.
0013 function time_start {
0014 time_beg=$(date +%s.%N)
0015 time_end=$time_beg
0016 time_run=0
0017 }
0018
0019 # time_start()
0020 #
0021 # Begin timing.
0022 function time_stop {
0023 time_end=$(date +%s.%N)
0024 time_run=$(echo "$time_end - $time_beg" | bc -l)
0025 echo "$time_run"
0026 }
Now knowing how long one or more items takes to process is as simple as:
0027 time_start 0028 task_to_run 0029 time_diff="$(time_stop)"
I wrapped the main functions and timed how long they take:
| Action | Time (s) |
|---|---|
| backup_dead_rt | 187.880756921 |
| logs_get_rt | 186.920260098 |
| logs_append_rt | 30.295236661 |
| logs_unique_rt | 146.004416903 |
| logs_abstract_rt | 16861.844717878 |
| logs_process_rt | 15.110010662 |
| plot_access_rt | .256452260 |
| plot_location_rt | .134897756 |
| logs_clean_rt | .325774132 |
| nginx_parser_rt | 18131.561209403 |
“nginx_parser_rt” is interactive and just represents how long I left the computer to sit there in the background. “logs_abstract_rt” represents 4.7 hours of straight processing. Oufe.
The old processing code was as follows:
0030 while read p; do
0031 IFS=' ' read -r -a cols <<< "$p"
0032 ip="${cols[0]}"
0033 country="$(geoiplookup $ip | cut -d " " -f 4)"
0034 country=${country::-1}
0035 timestamp="${cols[3]:1}"
0036 date="${cols[3]:1:-9}"
0037 time="${cols[3]:13}"
0038 method="${cols[5]:1}"
0039 path="${cols[6]}"
0040 response="${cols[8]}"
0041 echo "$date" >> out-date.txt
0042 echo "$country" >> out-ip.txt
0043 done <storage.txt
Line by line, we process each of the columns and pull out the important data. My thinking was that we may be paying for double-handling data, so I re-write this to the follows:
0044 # Clean data
0045 while IFS=' ', read ip z0 z1 timestamp zone method path type response size; do
0046 country="$(geoiplookup $ip | cut -d " " -f 4)"
0047 country=${country::-1}
0048 timestamp="${timestamp:1}"
0049 date="${timestamp::-9}"
0050 time="${timestamp:13}"
0051 zone="${zone::-1}"
0052 method="${method:1}"
0053 type="${type::-1}"
0054 echo "$date" >> out-date.txt
0055 echo "$country" >> out-ip.txt
0056 done <storage.txt
And the results of that is as follows:
| Action | Time (s) |
|---|---|
| backup_dead_rt | 168.895424672 |
| logs_get_rt | 205.790856856 |
| logs_append_rt | 26.603748814 |
| logs_unique_rt | 130.087103720 |
| logs_abstract_rt | 14435.241596371 |
| logs_process_rt | 11.781440252 |
| plot_access_rt | .175404852 |
| plot_location_rt | .114184411 |
| logs_clean_rt | .355445442 |
| nginx_parser_rt | 24555.858216634 |
It helped a little, but clearly we have to get a little more creative here…
I suspected I’m mostly getting screwed by the
geoiplookup command, that loads a database of a few MB and
then looks up the full locations details, which I then have to filter
out.
A better system is to load the database (of just a few MB) into RAM and then keep performing the searches against this for only the Country code. Additionally if we process the all of the logs in C++ we further save time.
I decided to use the maxmind’s geoip-api-c, which up until now, has worked great.
0057 //#define GEOIPDATADIR "geoip-api-c/data/" 0058 #define GEOIPDATADIR "/usr/share/GeoIP/" 0059 #define PACKAGE_VERSION "1.6.12"
If you try to use the database yourself, you will likely need to declare these variables. I had no end of trouble trying to link to the development library and I suspect it is broken since quite a while. It was much easier to directly include the files.
Note that the value for GEOIPDATADIR if for my system,
which I found through man geoiplookup. On Linux the
location appears to be: /usr/share/GeoIP/. Technically
there is a file in the repository at geoip-api-c/data/ -
but this did not work for me and was far too small. There is an update
tool, but this requires you to register 2.
0060 #include "geoip-api-c/libGeoIP/GeoIP_deprecated.c" 0061 #include "geoip-api-c/libGeoIP/GeoIP.c" 0062 #include "geoip-api-c/libGeoIP/GeoIPCity.c"
One little trap here is not including
GeoIP_deprecated.c.
0063 #include <stdarg.h> 0064 #include <stdbool.h> 0065 #include <stdio.h> 0066 #include <sys/time.h> 0067 0068 #define PARSER_VERSION "0.0.1" 0069 #define PARSER_LINE_LEN (256 * 256)
We might need a larger line length if we expect to have someone significantly testing our server. Most servers and browsers will allow URLs of 65k. In theory, each of those fields could be significantly large and this would cause issues with our parser.
0070 /* Source: https://stackoverflow.com/a/51336144/2847743 */
0071 int64_t currentTimeMillis(){
0072 struct timeval time;
0073 gettimeofday(&time, NULL);
0074 int64_t s1 = (int64_t)(time.tv_sec) * 1000;
0075 int64_t s2 = time.tv_usec / 1000;
0076 return s1 + s2;
0077 }
Some timing code that repeatedly proves to be useful.
0078 int flog(const char* format, ...){
0079 va_list args;
0080 va_start(args, format);
0081 fprintf(stderr, "[%li] ", currentTimeMillis());
0082 vfprintf(stderr, format, args);
0083 fprintf(stderr, "\n");
0084 va_end(args);
0085 }
Nice little wrapper around printf() to allow me to
automatically add a timestamp to the front of logs.
0086 /**
0087 * process()
0088 *
0089 * Process the logs.
0090 *
0091 * @param raw The raw nginx logs.
0092 * @param date The location of the date file.
0093 * @param date The location of the location file.
0094 **/
0095 void process(char* raw, char* date, char* loc){
0096 /* Setup buffers */
0097 char buff[PARSER_LINE_LEN + 1];
0098 /* Setup files */
0099 FILE* fraw = raw != NULL ? fopen(raw, "r") : NULL;
0100 FILE* fdate = date != NULL ? fopen(date, "a") : NULL;
0101 FILE* floc = loc != NULL ? fopen(loc, "a") : NULL;
0102 if(fraw == NULL){
0103 flog("Could not open '%s' for parsing", raw);
0104 return;
0105 }
0106 /* Setup GeoIp */
0107 GeoIP* gi = GeoIP_open(GEOIPDATADIR "GeoIP.dat", GEOIP_MEMORY_CACHE | GEOIP_CHECK_CACHE);
0108 /* Loop over the file */
0109 while(fgets(buff, PARSER_LINE_LEN, fraw)){
0110 int x = 0;
0111 char* ip = NULL;
0112 char* date = NULL;
0113 char* time = NULL;
0114 char* path = NULL;
0115 char* t = strtok(buff, " ");
0116 while(t != NULL){
0117 switch(x++){
0118 case 0 :
0119 ip = t;
0120 break;
0121 case 1 :
0122 case 2 :
0123 /* Do nothing */
0124 break;
0125 case 3 :
0126 date = t + 1;
0127 t[12] = '\0';
0128 time = t + 13;
0129 break;
0130 case 4 :
0131 case 5 :
0132 /* Do nothing */
0133 break;
0134 case 6 :
0135 path = t;
0136 break;
0137 default :
0138 /* No more of interest, quit early */
0139 t = NULL;
0140 break;
0141 }
0142 /* Check if we can stop tokenizing early */
0143 if(t == NULL){
0144 break;
0145 }else{
0146 t = strtok(NULL, " ");
0147 }
0148 }
0149 if(ip != NULL && floc != NULL){
0150 char* code = GeoIP_country_code_by_addr(gi, ip);
0151 fprintf(floc, "%s\n", code);
0152 }
0153 if(date != NULL && fdate != NULL){
0154 fprintf(fdate, "%s\n", date);
0155 }
0156 }
0157 }
A few tricks going on here. Firstly note the use of the
strtok() function that creates tokenized strings in-place.
The second trick is that we only grab the interesting data and we drop
everything else as soon as possible. We try not to waste cycles
processing data we have no plan to use.
0158 /**
0159 * help()
0160 *
0161 * Display program help.
0162 *
0163 * @param argc Number of arguments.
0164 * @param argv Pointer to the arguments.
0165 * @param x The current offset into the arguments.
0166 * @return The new offset into the arguments.
0167 **/
0168 int help(int argc, char** argv, int x){
0169 flog("./parser [OPT]");
0170 flog("");
0171 flog(" OPTions");
0172 flog("");
0173 flog(" -d Append data to a date file");
0174 flog(" <STR> Location of date file");
0175 flog(" -h Display this help and quit");
0176 flog(" -l Append data to a location file");
0177 flog(" <STR> Location of location file");
0178 flog(" -r The raw nginx logs to be read");
0179 flog(" <STR> Location of nginx logs");
0180 flog(" -v Display version information");
0181 return x;
0182 }
0183
0184 /**
0185 * main()
0186 *
0187 * Process the command line arguments.
0188 *
0189 * @param argc The number of arguments provided.
0190 * @param argv The arguments provided.
0191 * @return The exit status of the program.
0192 **/
0193 int main(int argc, char** argv){
0194 static char* raw = NULL;
0195 static char* date = NULL;
0196 static char* loc = NULL;
0197 for(int x = 0; x < argc; x++){
0198 if(argv[x][0] == '-'){
0199 switch(argv[x][1]){
0200 case 'd' :
0201 date = argv[++x];
0202 break;
0203 case 'h' :
0204 x = help(argc, argv, x);
0205 return EXIT_SUCCESS;
0206 case 'l' :
0207 loc = argv[++x];
0208 break;
0209 case 'r' :
0210 raw = argv[++x];
0211 break;
0212 case 'v' :
0213 flog("Version: %s", PARSER_VERSION);
0214 break;
0215 default :
0216 flog("Unknown option '%s'", argv[x]);
0217 break;
0218 }
0219 }else{
0220 flog("Unknown parameter '%s'", argv[x]);
0221 }
0222 }
0223 if(raw != NULL){
0224 process(raw, date, loc);
0225 }else{
0226 flog("Require raw logs to be processed");
0227 return EXIT_FAILURE;
0228 }
0229 return EXIT_SUCCESS;
0230 }
The result?
| Action | Time (s) |
|---|---|
| backup_dead_rt | 154.661541988 |
| logs_get_rt | 267.600526311 |
| logs_append_rt | 30.361294628 |
| logs_unique_rt | 126.968953909 |
| logs_abstract_rt | 44.061660188 |
| logs_process_rt | 11.607090069 |
| plot_access_rt | .494797933 |
| plot_location_rt | .318292984 |
| logs_clean_rt | .562272088 |
| nginx_parser_rt | 8559.049334771 |
A 383x speed-up (or 38,268% speed-up) - not bad at all!
Encase you are wondering, this is the current server statistics:
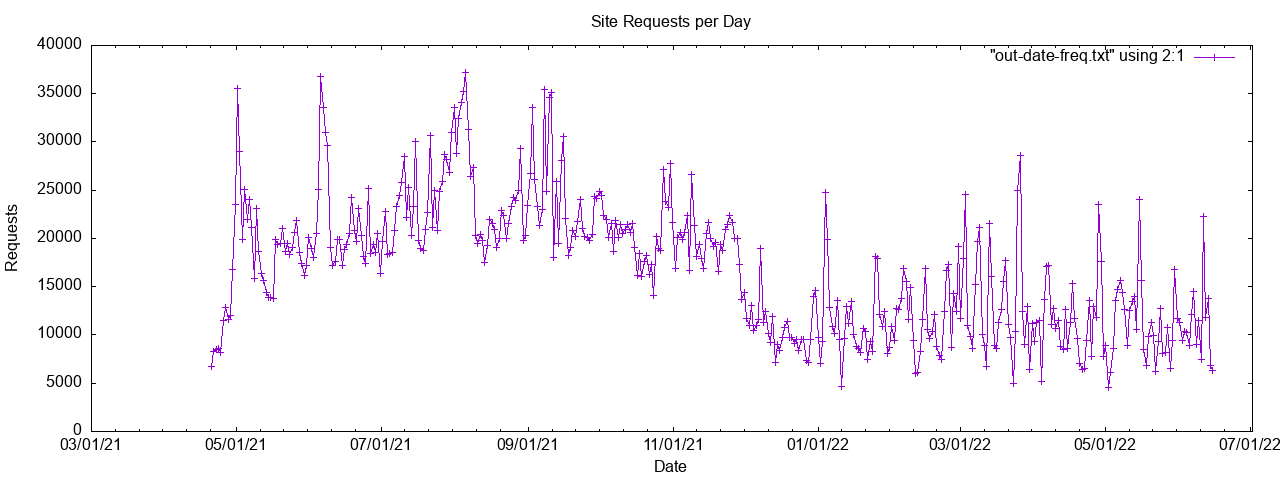

The reason I needed to have this better processed is that my server now hosts static files for another business and I need to ensure the server resources stand up well. If I suddenly start seeing significant increases in traffic I may consider upgrading the server to accommodate.