
This post refers to the project that can be found here -
specifically at commit b8c47c2. After some period of time,
it’s expected that some progress will be made with this project,
invalidating some of the ideas and concepts discussed here.
Free Comment is an open source commenting system I wrote for allowing my website to receive feedback from the public about the various articles I write. It has been an interesting project and I believe the “end-result” is a relatively nice and simple project.
The reason for creating this project is I wanted a free and open commenting system to add to my website. I considered multiple other free options, all either too complex for the task in hand or offer too much for my simple little website.
Firstly, we speak about the requirements of the project:
lynx and dillio web
browsersThe system has the following limitations as a result of the requirements:
There is more discussion about this in the “Bugs” section.
NOTE: These are problems that should have a solution in the near future.
The general setup is a Java based web server, chosen for it’s ease of programming and relative stability. Being compatible on all systems that run Java (Linux, Windows, Mac, etc) is also desirable to most people, widening the net for those able to use this system. I also like that Java is able to handle program crashes and recover from them, regardless of what bad code ends up being written. This means the software should add stability and resilience against most forms of attack.
I must warn those who often develop web based systems - I do not. What you will see is a long string of hacks and assumptions that may make you cringe. Read the code at your own peril. At least it’s comment (runs away).
Now onto the meat of this operation.
Here is a diagram of the system architecture:
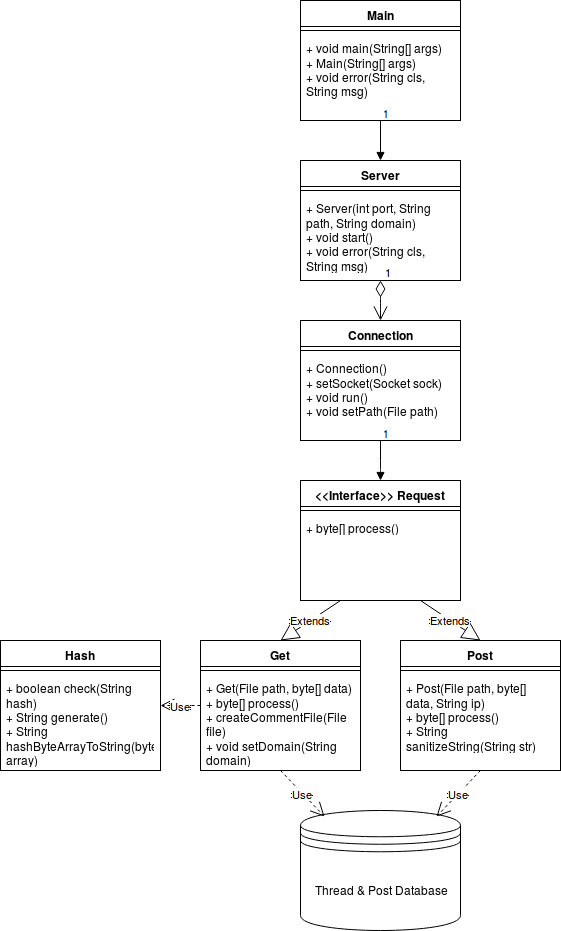
This diagram was generated using draw.io, the XML file can be found here.
Now we will describe the purpose of each class…
Main.java: Here we accept the command line arguments and generally nurse the server into existence with it’s various settings that have been requested.
Server.java: This class is responsible for building the server up and sitting in several infinite loops, waiting for something exciting to happen. How fun.
Connection.java: Now we have code that reads the top
of the request and decides whether it is a GET or
POST request. If neither, then it gracefully kills itself
like some shamed Japanese Samurai.
Get.java: This is where we either retrieve threads or generate new comment threads.
Post.java: This is where we append user data to an existing comment thread.
Hash.java: Here we have secure level hashing, but in this case for generating new filenames for the comment threads. Ideally we want to avoid double naming (there is a check just encase of this rare occurrence of a collision in the wild), but also we want to avoid crawlers trying to store all the user comments. It could take longer than the lifetime of the Universe to crawl through the different comment threads in a brute force fashion - in fact it’s unlikely you would ever randomly find one. This leaves only users who actually need the data making the request, or at least that’s the idea.
This project can be considered to be “secure enough”. The vulnerabilities are categorized into two sections: resource blocking and system access. This project, at this commit should not allow a third party to access a shell on the server, but it is possible to crash the server or keep the server exceptionally busy. These bugs are discussed in the “Bugs” section.
There are a few bugs known about and they will fixed when time permits me to do so. A description is below of a few of these issues.
[Feature] Link generation doesn’t include portThis bug is simply annoying, as links may have to be adapted if the service is running on a port other than port 80.
A detailed description can be found here.
[Security] No filtering for POSTsThis bug is a serious security issue. Any person can keep the server too busy to be used by other users, or in the worst case scenario can crash the server by using up all available disk space.
A detailed description can be found here.
[Security] Filter spam thread generationThis is another serious security issue for the same reason above - the server’s resources could be maximised and therefore eventually cause a denial of service. Another potential issue is that a third party may make more comment threads, a.k.a more files than the underlying filesystem can handle. Although rarely seen, most systems will have a maximum number of files that can be created with unexpected circumstances in those scenarios.
A detailed description can be found here.
[Security] No defence against resource usageThis is another security issue, not as problematic as the ones previous as it simply describes how the server ports may be taken up by an attacker by either performing slow loris or DoS/DDoS. This isn’t as important as the other two security issues, as the attack will eventually pass and leave the server perfectly stable and most VPS services will also defend your service against this.
A detailed description can be found here.
Please refer to the GitHub issues tracking system for information about future work on this project.
Please leave a comment using this system - I would love to hear feedback of any kind.
Comment Model
To avoid using some database model, I decided to simply use files and the disk. It should be relatively fast on a VPS SSD and ultimately should be simple to understand.
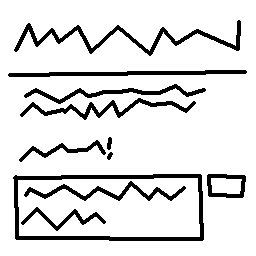
On the disk, each thread is represented by it’s filename. Inside is the following structure:
Adding a comment is as simple as appending to the end of the file - a relatively simple operation to perform.
In hindsight, the form submit would have been added to the request itself - but in the case that the system was to be archived, I wanted each comment thread file to be viewable in a browser and served by a simple web browser. Potentially some important history could be captured by this system and it’s important we are able to preserve this.