

The Netizens team is a student led hacking team, a group part of the University of Hertfordshire that has many cyber security projects. These projects come in many forms, including hardware, software, procedures and much more. One of these interests has been the Fake News Challenge, or FNC as we have come to refer to it.

Our thinking is, “if you can detect fake news, you can detect malicious social hacking”. This could be in the form of phishing emails, scamming websites or malicious programs. The ability to detect human deception attempts allows for a whole class of systems that detect users. Bringing artificial intelligence to these systems allows for smarter detection.
Fake news, as defined on the FNC site, by the New York Times:
0001 Fake news, defined by the New York Times as “a made-up story with an 0002 intention to deceive” 1, often for a secondary gain, is arguably one of the 0003 most serious challenges facing the news industry today. In a December Pew 0004 Research poll, 64% of US adults said that “made-up news” has caused a 0005 “great deal of confusion” about the facts of current events 2.
The goal of the competition is to explore how modern techniques in machine learning and artificial intelligence can be used to fact check news sources. Doing so is considered if a time consuming and often difficult task for experts, but automating the process with stance detection allows for fast classification of news sources if accurate.
More can be found here.
The formalism of the stance classification is defined as follows:
0006 Input 0007 A headline and a body text - either from the same news article or from 0008 two different articles. 0009 Output 0010 Classify the stance of the body text relative to the claim made in the 0011 headline into one of four categories: 0012 1. Agrees: The body text agrees with the headline. 0013 2. Disagrees: The body text disagrees with the headline. 0014 3. Discusses: The body text discuss the same topic as the headline, but 0015 does not take a position 0016 4. Unrelated: The body text discusses a different topic than the 0017 headline
The scoring is done as follows:
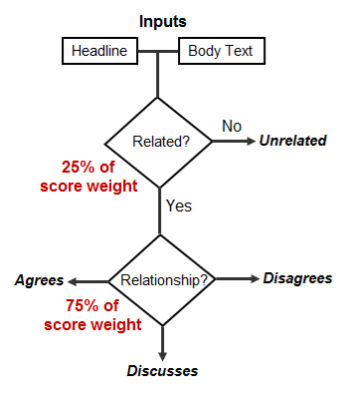
There are several rules associated with the competition:
Our initial design thinking was to produce a framework that would allow us to attempt several different ideas, having the data input and data output all handled by the program. The next line of thinking was to have the program automated via the terminal, so that we could test multiple implementations over some long period of time and come back and analyse the results.
This was done is Java, as it was considered an easy language to implement this in and allows for debugging. Our team members also use multiple different development OSes, so we decided to use a language that works on most. In hindsight, a data orientated (such as R or Python) would have been more appropriate - live and learn.
For our initial design, we implemented 1st nearest neighbour. This gave us very poor results, not matching anything other than one label.
Due to implementation, running the program was taking 10 hours, for single nearest neighbour! We stored our database in RAM as strings and casted to numeric values each time - that was incredibly slow. After realising our mistake, we got our timing down to about a minute for analysing and matching - much better!
We later found a few more problems in our coded:
A re-write soon sorted this and were able to validate that our code was indeed working as intended. Impressively, even for K values larger than 100, we were still able to classify our data in the order of minutes.
Please refer to our snapshot repository for the source code for our version of the software for the competition.
TODO: Discuss the code layout.
The code can be visualised as follows (source):
As you’ll see, everything has been completely written from scratch - not a single line has been borrowed from somewhere. If anything, this makes this project impressive within it’s own right.
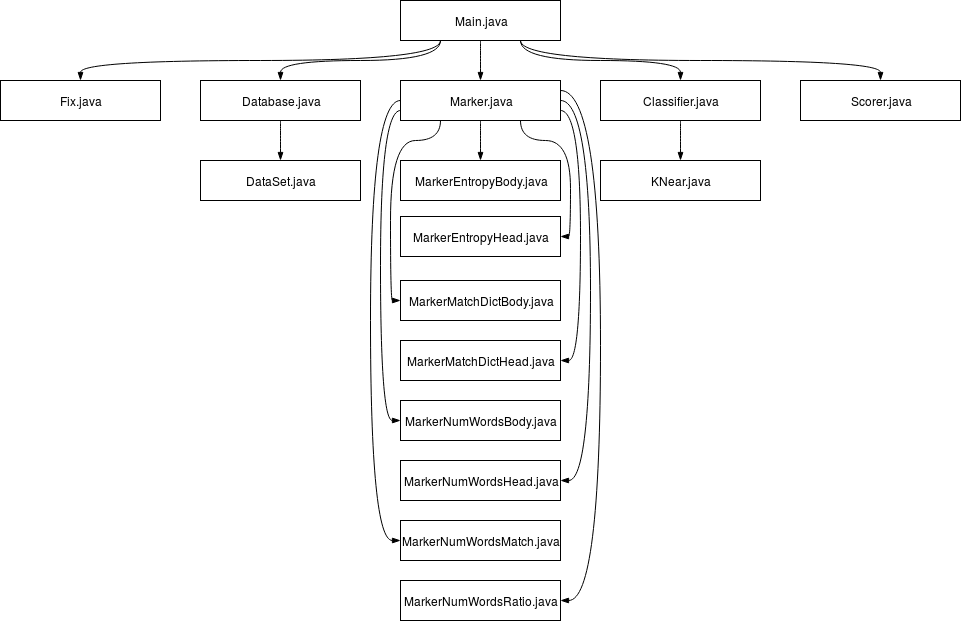
The following is a description of each class and it’s purpose:
Further comments exist in the source files themselves.
Running the following:
0018 ant; java -jar fnc.jar -h
Reveals:
0019 ./fnc.jar [OPT] 0020 0021 OPTions 0022 0023 -c --clss Classified data 0024 <FILE> CSV titles file 0025 <FILE> CSV bodies file 0026 -h --help Displays this help 0027 -k --kner Set the K for k-nearest 0028 <INT> Number of nearest 0029 -j --jobs Set the number of jobs to run 0030 <INT> Number of jobs 0031 -m --mode Set the mode 0032 knear (def) k-nearest neighbours 0033 -r --runs Set the number of runs 0034 <INT> Number of runs 0035 -u --ucls Unclassified data 0036 <FILE> CSV titles file 0037 <FILE> CSV bodies file 0038 -f --fix Fixes the results to it's original form. 0039 <FILE> The original whole titles database
The options are self explanatory, but of interest to us is in particular is the K value, which allows us to define how many nearest neighbours we take into consideration. In the results section, we see the outcome of varying our K value.
The following is the Marker.java interface (without
comments):
0040 public interface Marker{
0041 public String getName();
0042 public double analyse(DataSet ds, int y);
0043 }
As you can see, it’s very simple. Each of the makers is given a
reference name, as well as accepting the data to analyse at a given
position and then returning a double value associated with
it. This double value can be the full range of
double, where it is normalised after.
We have the following types of markers:
NOTE: We actually ended up turning off the dictionary match marker, as this actually made the matching process harder.
During our initial testing, we were getting results above 85% when classifying 80% of the training data, using 20% of the training data to train.
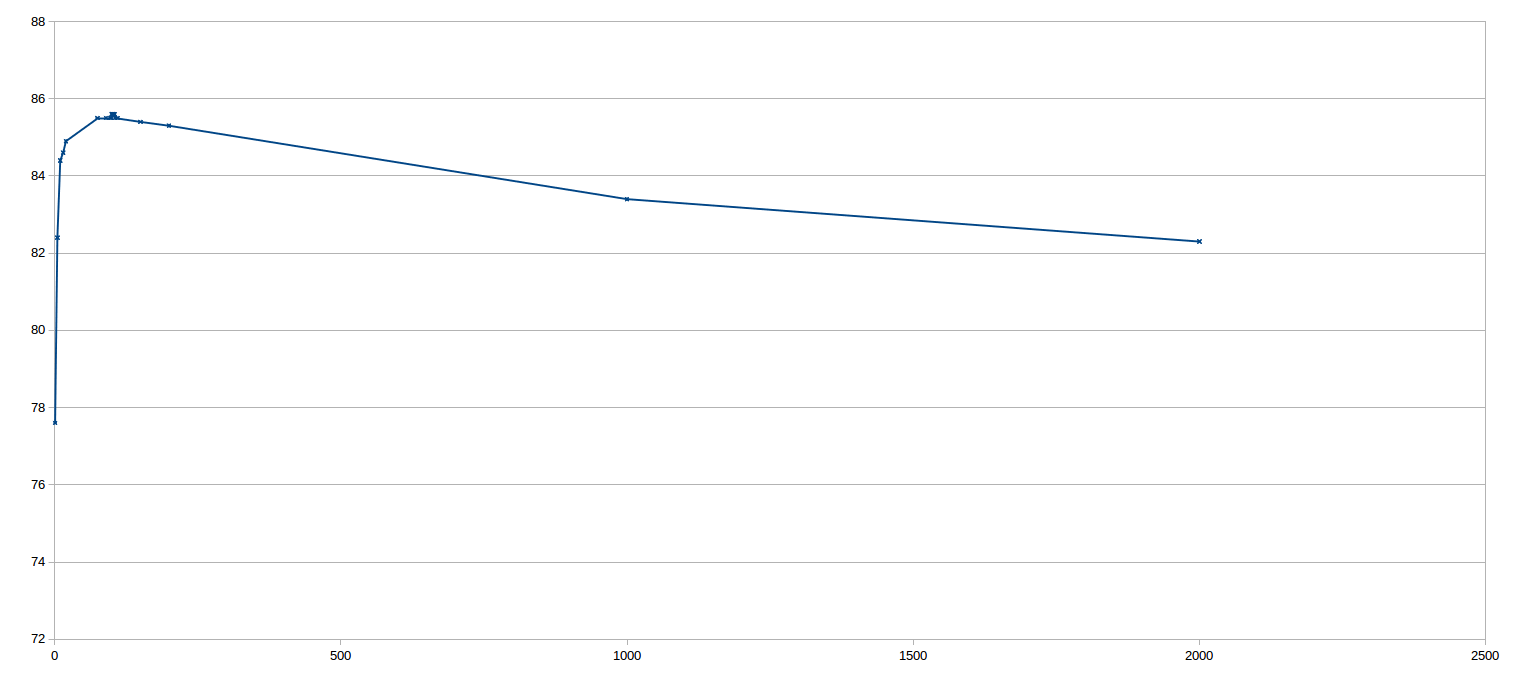
Varying the K value had a large affect and there was clearly an advantage to looking at about 105 of a node’s nearest neighbours for the purpose of classification.
Our actual results were 83.0% using the new test data, trained with the previously released training data. This is considerably lower than our original classification, but this is understandable given the amount of overlap in our previous data training data.
One additional restraint added at the end of the competition was that 1 hour before closure, at 23:59 GMT on the 2nd of June, the results table would go “dark” in order to add some additional mystery to who the winner is.
Below we have the results table, pulled at 22:56 GMT:
0044 submission_pk User score 0045 404231 seanbaird 9556.500 (1) 0046 404214 athene 9550.750 (2) 0047 404189 jaminriedel 9521.500 (3) 0048 404185 shangjingbo_uiuc 9345.500 (4) 0049 404142 enoriega87 9289.500 (5) 0050 404228 OSUfnc2017 9280.500 (6) 0051 404205 florianmai 9276.500 (7) 0052 404197 humeaum 9271.500 (8) 0053 403966 pebo01 9270.250 (9) 0054 404194 gtri 9243.000 (10) 0055 404226 jamesthorne 9189.750 (11) 0056 404133 Soyaholic 9146.250 (12) 0057 403872 ezequiels 9117.500 (13) 0058 404233 Tsang 9111.500 (14) 0059 404129 siliang 9103.750 (15) 0060 404062 neelvr 9090.750 (16) 0061 404080 stefanieqiu 9083.250 (17) 0062 404215 htanev 9081.250 (18) 0063 404221 tagucci 9067.000 (19) 0064 404070 saradhix 9043.500 (20) 0065 404137 acp16sz 8995.750 (21) 0066 404176 Gavin 8969.750 (22) 0067 404092 JAIST 8879.750 (23) 0068 404114 subbareddy 8855.000 (24) 0069 404025 amblock 8797.500 (25) 0070 404036 annaseg 8797.500 (25) 0071 403978 Debanjan 8775.250 (26) 0072 404183 johnnytorres83 8761.750 (27) 0073 404086 avineshpvs 8539.500 (28) 0074 403858 bnns 8349.750 (29) 0075 404108 gayathrir 8322.750 (30) 0076 404076 MBAN 8321.000 (31) 0077 404209 martineb 8273.750 (32) 0078 403809 contentcheck 8265.750 (33) 0079 404204 vivek.datla 8125.750 (34) 0080 404227 vikasy 7833.500 (35) 0081 404175 barray 7778.250 (36) 0082 404232 MicroMappers 7420.250 (37) 0083 404082 borisnadion 7160.500 (38) 0084 403913 etrrosenman 7106.750 (39) 0085 404033 agrena 6909.750 (40) 0086 404056 gpitsilis 6511.750 (41) 0087 404224 mivenskaya 6494.750 (42) 0088 403851 rldavis 5617.500 (43) 0089 404065 isabelle.ingato 5298.500 (44) 0090 404049 daysm 4911.000 (45) 0091 404184 mrkhartmann4 4588.750 (46) 0092 404106 bertslike 4506.500 (47)
All-in-all, it seems as though we had 50 entries in total - so by extension some people entered when the score board finally went dark. Given our position in the table, if they randomly placed it is likely they placed above us. This means we placed a respectable 36-39 out of 50.
So now, we look at how things have gone in reflection.
Thinking about the implementation, I think we’re mostly happy to have travelled the road we have in terms of the learning experience involved with writing everything from scratch. Of course, given the opportunity again, I think we would possibly explore the idea of the using a higher level system for analysing the data, possibly as several different tools rather than one large rolled tool.
This also comes down to the classic “given more time”. Both the people on our team were extremely pressed for time with various happenings, both of us leaving the UK for other Countries, as well as many other University related pressures. This project really only saw a day perhaps in a month - so it’s impressive it got this far.
Speaking of being impressed, it’s surprising how far you can get with just a k-nearest neighbour algorithm. It’s certainly fast! You could very easily label data on the fly, possibly even in browser per client if you were using this as a web tool.
We didn’t come last! Given our limited time, our long path to solving the problem, miraculously we didn’t even come last in solving the problem. 83.0% classification of some completely unknown data is really not too bad at all.
The competition itself was run very nicely, given the number of people competing from various Countries and time zones. Some things could have been done better, but considering this was their first attempt and they were not sure how successful it would be - I think this is an impressive accomplishment to those involved. Hats off to them.
Lastly, this competition is called “FNC-1”, the “1” implying it’s the first in a series. I think we would definitely be interested in competing next year!